I wanted to show my co-worker Ryan the work I'd done with the noise functions over the weekend, since he's also interested in graphics development. I grabbed the JOCL and JOGL libraries and downloaded the Demo code from github, set up everything in Eclipse and...
Failure. The OpenCL library refuses to set up a shared buffer on my Mac. "Oh well" I though, "I can still show him on my work desktop". Spent a few minute replicating the same environment there and...
More failure. The CL subsystem still refuses to create a shared buffer, though it appears that this has something to do with Mesa.
Granted, neither of these machines is exactly on the bleeding edge or possesses a GPU, but they should still be able to fall back to the CPU for operations. I suppose I could try porting the noise functions out of OpenCL and into a vertex shader, but I can't really spend that kind of time showing off to my coworkers during work hours.
I guess I'll try attacking the Mac side when I get home tonight if I have time. It seems to revolve around setting the CL_CGL_SHAREGROUP_KHR value on the CLGL context. Having a third party library to media the interaction with things like OpenGL and OpenCL is supposed to smooth away platform differences like this or at least report on a platform that didn't support a particular feature with a reasonable error message, one would hope.
Monday, November 26, 2012
Sunday, November 25, 2012
Weekend diversions, software
So, for whatever reason, I feel my computer UI should look cooler. Not be more functional (though hopefully not be incredibly less functional), but just look cooler. Watching movies like Iron Man, Tron: Legacy, and Ghost in the Shell leaves me feeling like there's a lot of potential being wasted, if not in utility, at least in presentation.
Tron: Legacy in particular has a lot of UI elements scattered about, and for all its failings in story telling, has some of my favorite art direction of any film. Happily, there's information out there by some of the people who worked on it about how they did some of the elements in the film:
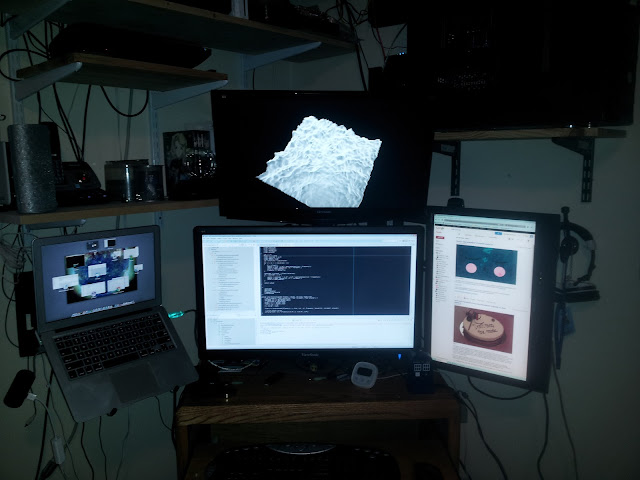
I'm still pretty far away from transforming a 4D noise function into a set of isosurfaces bounded by a sphere, but I have been able to get a 2D point mesh to deform over time by passing it through a 3D noise function (actually a whole set of different noise functions implemented in OpenCL, which I found here). It's visible in this picture of my workspace on the top monitor, though a static image doesn't really do it justice.
Tron: Legacy in particular has a lot of UI elements scattered about, and for all its failings in story telling, has some of my favorite art direction of any film. Happily, there's information out there by some of the people who worked on it about how they did some of the elements in the film:
I decided to see if I could approximate something like the effect shown, so I started fiddling with what tools I could find. I started by trying to get a CUDA development environment working, but even though nVidia says they support development in Eclipse, they only actually do so for OSX and Linux. If you're developing in Windows, you have to be using Visual Studio 2008 or 2010. And not Visual Studio Express either, but minimum Visual Studio Professional which retails starting at $600. I'm way more likely to reformat my machine to Linux than I am to fork over $600 to MS just to good off with visual effects, so I started looking into alternatives. Happily there are some pretty nice Java libraries for providing bindings to OpenGL and OpenCL which are usable independent of what windowing system you happen to be using. I tend to prefer SWT because even though it's a little harder to get off the ground, I feel it gives you a better experience due to the thin wrapping of native controls.
When fixing Quorra, there was an element in the DNA interface called the Quorra Heart which looked like a lava lamp. I generated an isosurface from a perlin-noise volume, using the marching cubes function found in the Geometric Tools WildMagic API, a truly wonderful lib for coding biodigital jazz, among other jazzes.
I'm still pretty far away from transforming a 4D noise function into a set of isosurfaces bounded by a sphere, but I have been able to get a 2D point mesh to deform over time by passing it through a 3D noise function (actually a whole set of different noise functions implemented in OpenCL, which I found here). It's visible in this picture of my workspace on the top monitor, though a static image doesn't really do it justice.

Weekend diversions, hardware
I haven't spent much time on the music re-org lately. I've boiled the effort down to taking a chunk of artists at a time, passing them through MusicBrainz Picard to properly tag and rename them and then searching for duplicated files after the renaming.
I have however redone the arrangement of computers at home. I was previously running a 23" LG 3D monitor, plus an older 17" ViewSonic 4:3 ratio monitor to the left of the main screen. I've moved the 23 inch to my wife's machine, replacing her 20 inch widescreen ViewSonic. In place of the 23" LG as my primary, I now have a 27" ViewSonic LED monitor. Directly above that I have a 24" ViewSonic LED. To my left is now a wall mounted laptop stand which holds my work machine, and to my left is Kat's old 20 inch, rotated into portrait mode for reading and browsing long form content.

The center monitor can serve dual duty as the primary screen for the MacBook Air or my desktop, depending on whether I'm working or not. The top screen gives me a target for graphical development, media playing, or if the primary monitor is being driven by the Mac, as a conventional aspect monitor for my desktop.
Graphics cards that will drive three monitors concurrently are surprisingly hard to come by. It appears that for nVidia at least, you need a GeForce 6xx series card at least. I actually initially bought a higher end GeForce 5xx that had 3 outputs, only to find if I tried to enable the third monitor it would shut off one of the other two. I didn't feel particularly like living on the bleeding edge, so I bought a more conservative GeForce GTX 650 TI which still manages to blow the doors off my old GeForce GTX 275, which in turn was still perfectly adequate for all of my actual gaming and development needs (with the exception of triple monitor support).
I'm still not completely happy with my mouse and keyboard. The mouse isn't too bad, a Logitech Performance MX, but it seems to be subject to occasional wireless interference and the mouse wheel is virtually impossible to click as a middle mouse click. The keyboard is an ancient Logitech Cordless Elite Duo (long since separated from the mouse half of the Duo). It's nearly 10 years old and has a good feed to the keys, but it's wireless receiver is a big dongle that has a now useless portion for hooking up to your PS2 keyboard port. Unfortunately I haven't find a newer Logitech keyboard that satisfies all my needs
I have however redone the arrangement of computers at home. I was previously running a 23" LG 3D monitor, plus an older 17" ViewSonic 4:3 ratio monitor to the left of the main screen. I've moved the 23 inch to my wife's machine, replacing her 20 inch widescreen ViewSonic. In place of the 23" LG as my primary, I now have a 27" ViewSonic LED monitor. Directly above that I have a 24" ViewSonic LED. To my left is now a wall mounted laptop stand which holds my work machine, and to my left is Kat's old 20 inch, rotated into portrait mode for reading and browsing long form content.
The center monitor can serve dual duty as the primary screen for the MacBook Air or my desktop, depending on whether I'm working or not. The top screen gives me a target for graphical development, media playing, or if the primary monitor is being driven by the Mac, as a conventional aspect monitor for my desktop.
Graphics cards that will drive three monitors concurrently are surprisingly hard to come by. It appears that for nVidia at least, you need a GeForce 6xx series card at least. I actually initially bought a higher end GeForce 5xx that had 3 outputs, only to find if I tried to enable the third monitor it would shut off one of the other two. I didn't feel particularly like living on the bleeding edge, so I bought a more conservative GeForce GTX 650 TI which still manages to blow the doors off my old GeForce GTX 275, which in turn was still perfectly adequate for all of my actual gaming and development needs (with the exception of triple monitor support).
I'm still not completely happy with my mouse and keyboard. The mouse isn't too bad, a Logitech Performance MX, but it seems to be subject to occasional wireless interference and the mouse wheel is virtually impossible to click as a middle mouse click. The keyboard is an ancient Logitech Cordless Elite Duo (long since separated from the mouse half of the Duo). It's nearly 10 years old and has a good feed to the keys, but it's wireless receiver is a big dongle that has a now useless portion for hooking up to your PS2 keyboard port. Unfortunately I haven't find a newer Logitech keyboard that satisfies all my needs
- Large, easily accessible media keys, preferably with a dial for volume. If I have to hit a 'Fn' key to use a media key, then it's a non-starter
- Keys that are at least a centimeter high and depress most of their height. I can't stand these keys that barely move.
- The Home/End/PgUp/PgDown/Ins/Del keys need to be arranged in a 3x2 grid. Many, if not most Logitech keyboard use a 2x3 layout that has a double height delete key and no insert key.
- No gaming keys. I have a gaming keyboard I plug in when I want to play World of Warcraft, but 90% of the time it would be taking up too much space on my keyboard tray.
Monday, November 12, 2012
Fixing my music... part 3
So I now officially know more about ID3 tags than I ever really wanted to know. Actually I think I may have passed that mark when I did the original work on the Mp3agic library to debug why it wouldn't parse my tags. Regardless, I now know even more.
Many of the files I'm trying to dedupe turn out to have exactly the same size. I have to attribute this to the likelihood that MP3 frames have some minimum size, so if the difference between two of them is only in a few frames that are under the minimum size, the total file size will be the same.
I've spent the bulk of my evening trying to figure out how to meaningfully compare the ID3 tag information from two files, and it ended up involving a lot of extending of the Mp3agic functionality. The library itself seems to focus on preservation of data from the source file. For instance, all text fields can be encoded with one of four possible encodings. If the same data is in two different files with two different encodings, the library preserves that information, so if you compare the two frames, they show up as different, even though the difference is actually academic. They represent the exact same information, but happen to have been written out by two different pieces of software that each had their own idea about the best encoding to use. I have my own opinion on the best encoding to use. It's called "UTF-8 or GTFO".
Additionally, a number of differences I'm seeing are attributable to the variations between sub versions of ID3v2. For instance, ID3v2.4 supports the TSOP frame type, which is for the artist name as it should be used for sorting, i.e. 'Beatles' instead of 'The Beatles'. ID3v2.3 didn't support this tag, but some programs apparently started populating a field called XSOP, which serves the same purpose. 2.3 also had a number of different fields for parts of the recording date, which have collectively been replaced by a single TDRC field which stores the full date. Mp3agic could smooth this over by supporting a normalized representation of the data which doesn't care about encoding and does its best to migrate data into a canonical internal format, but it doesn't.
Many of the files I'm trying to dedupe turn out to have exactly the same size. I have to attribute this to the likelihood that MP3 frames have some minimum size, so if the difference between two of them is only in a few frames that are under the minimum size, the total file size will be the same.
I've spent the bulk of my evening trying to figure out how to meaningfully compare the ID3 tag information from two files, and it ended up involving a lot of extending of the Mp3agic functionality. The library itself seems to focus on preservation of data from the source file. For instance, all text fields can be encoded with one of four possible encodings. If the same data is in two different files with two different encodings, the library preserves that information, so if you compare the two frames, they show up as different, even though the difference is actually academic. They represent the exact same information, but happen to have been written out by two different pieces of software that each had their own idea about the best encoding to use. I have my own opinion on the best encoding to use. It's called "UTF-8 or GTFO".
Additionally, a number of differences I'm seeing are attributable to the variations between sub versions of ID3v2. For instance, ID3v2.4 supports the TSOP frame type, which is for the artist name as it should be used for sorting, i.e. 'Beatles' instead of 'The Beatles'. ID3v2.3 didn't support this tag, but some programs apparently started populating a field called XSOP, which serves the same purpose. 2.3 also had a number of different fields for parts of the recording date, which have collectively been replaced by a single TDRC field which stores the full date. Mp3agic could smooth this over by supporting a normalized representation of the data which doesn't care about encoding and does its best to migrate data into a canonical internal format, but it doesn't.
Sunday, November 11, 2012
Fixing my music... part 2
The analysis code for organizing my music collection was fun to write. I'm using my basic environment of Java 7, Guava, and SLF4j. For serialization I'm using Jackson, and for stopwatch functionality I'm using Spring, which has to be the stupidest possible reason to use spring, but since I'm using Maven for dependency management, it amounts to adding a line in a config file that say 'use spring'.
Going through 17k music files is prone to being slow, so I'm using multiple threads. I'm pretty sure I'm actually going to be bottlenecking on disk IO, since I'm hosting all these files on physical platters, not having a spare >80GB SSD to park them on. As I winnow down I may move them to the SSD so future operations are faster. Regardless, I still want the multiple threads because I'm going to be doing a lot of hash functions on each file, so I want to saturate my CPU's where I can at least. I have 8 cores (well.. 4 if you don't count hyper-threading) so I figured 6 threads wouldn't impact the responsiveness of the OS while I was running this, and it didn't.
However, using multiple threads is prone to race conditions, especially since I've got code that tries to report the progress through the data every 100 items processed or so.
Finally, Mp3agic, the MP3 parsing library I'm using, is a) not 100% bug free and b) further customized on my local machine from the distribution on Github. My initial work with Mp3agic was to submit some code to fix the handling of UTF-16 text data in the ID3 tags. Some IO refactoring had been done, and there was an issue with some code that was supposed to be counting characters and instead was counting bytes. This isn't normally an issue since mostly you just encounter UTF-8 with no multibyte characters. I mean, seriously, who *cough* Amazon *cough* would put UTF-16 into the comment field of an ID3 tag if they didn't have to. So I fixed that. However the Mp3agic code is written to work against File objects, and internally does a lot of seeking with a RandomAccessFile object when it parses the file. This strikes me as a waste because I've already turned the file into a byte[] so that I can hand it to the hashing function for the whole file hash, so I rewrite the MP3 parsing code to work directly against a byte[]. But that's a non-trivial change, and I can't run the unit tests on the library because I've broken some bits of the interface that I don't feel like fixing and that are of any use to me.
So, between the multiple threads, and the MP3 library instability, I want to make sure that my code is going to persist all the data it has so far every so often, and in addition, if I restart the program, it will load this checkpoint data and only work on stuff it hasn't already done. I actually didn't initially do this, but discovered a small bug in my Mp3agic changes after processing about 500 files on my first run, so I went ahead and implemented it.
Of course, having done that, it went all the way through the files on the next pass. The final result is about 500 files that aren't parsable, and 5393 unique audio hashes. Of those, only 71 have only one file, and therefore aren't duped. So maybe I'll be able to move to the SSD processing pretty soon. On the other hand I'm not sure I want to arbitrarily delete all but one of each of this files. Ideally I'd like to make sure I keep the file with the most complete and accurate, but that's not really going to be easy to determine heuristically.
On the other hand, the low hanging fruit is there. Fully duplicated files. There are 10944 file hashes, with 5204 of them having more than one file. So right off the back I should be able to get rid of about 5k files.
Going through 17k music files is prone to being slow, so I'm using multiple threads. I'm pretty sure I'm actually going to be bottlenecking on disk IO, since I'm hosting all these files on physical platters, not having a spare >80GB SSD to park them on. As I winnow down I may move them to the SSD so future operations are faster. Regardless, I still want the multiple threads because I'm going to be doing a lot of hash functions on each file, so I want to saturate my CPU's where I can at least. I have 8 cores (well.. 4 if you don't count hyper-threading) so I figured 6 threads wouldn't impact the responsiveness of the OS while I was running this, and it didn't.
However, using multiple threads is prone to race conditions, especially since I've got code that tries to report the progress through the data every 100 items processed or so.
Finally, Mp3agic, the MP3 parsing library I'm using, is a) not 100% bug free and b) further customized on my local machine from the distribution on Github. My initial work with Mp3agic was to submit some code to fix the handling of UTF-16 text data in the ID3 tags. Some IO refactoring had been done, and there was an issue with some code that was supposed to be counting characters and instead was counting bytes. This isn't normally an issue since mostly you just encounter UTF-8 with no multibyte characters. I mean, seriously, who *cough* Amazon *cough* would put UTF-16 into the comment field of an ID3 tag if they didn't have to. So I fixed that. However the Mp3agic code is written to work against File objects, and internally does a lot of seeking with a RandomAccessFile object when it parses the file. This strikes me as a waste because I've already turned the file into a byte[] so that I can hand it to the hashing function for the whole file hash, so I rewrite the MP3 parsing code to work directly against a byte[]. But that's a non-trivial change, and I can't run the unit tests on the library because I've broken some bits of the interface that I don't feel like fixing and that are of any use to me.
So, between the multiple threads, and the MP3 library instability, I want to make sure that my code is going to persist all the data it has so far every so often, and in addition, if I restart the program, it will load this checkpoint data and only work on stuff it hasn't already done. I actually didn't initially do this, but discovered a small bug in my Mp3agic changes after processing about 500 files on my first run, so I went ahead and implemented it.
Of course, having done that, it went all the way through the files on the next pass. The final result is about 500 files that aren't parsable, and 5393 unique audio hashes. Of those, only 71 have only one file, and therefore aren't duped. So maybe I'll be able to move to the SSD processing pretty soon. On the other hand I'm not sure I want to arbitrarily delete all but one of each of this files. Ideally I'd like to make sure I keep the file with the most complete and accurate, but that's not really going to be easy to determine heuristically.
On the other hand, the low hanging fruit is there. Fully duplicated files. There are 10944 file hashes, with 5204 of them having more than one file. So right off the back I should be able to get rid of about 5k files.
Fixing my music... part 1
I've been meaning to spend some time organizing my home media. My ripped movies are already pretty well organized, and I'm happy to rely on XBMC to maintain the metadata for them. However, my music files are a total disaster. There's an order of magnitude more of them, and they have self-contained metadata. There's a ton of duplication of music in various states of file name format, completeness of metadata, upgraded audio and so on.
I've finally decided to tackle it. I have almost 17k MP3 files currently copied to my desktop machine, basically by taking all the collections I could find in various places and dumping them all together. There's easily going to be 66% duplication in there because I've just copied wholesale both my main storage and the results of previous attempts at organization in there, which includes a big pass with MusicBrainz Picard that only got half done, as well as the results of having pushed all my music to the Amazon cloud when they said it was going to be free, and then pulling it all back down when they changed their minds. It may go back up, but only after I've curated the hell out of it.
Well, the analysis step just finished and has produced a 5 MB JSON file with the salient details. I'll start working on identifying the files I can junk, and the files I need to curate.
I've finally decided to tackle it. I have almost 17k MP3 files currently copied to my desktop machine, basically by taking all the collections I could find in various places and dumping them all together. There's easily going to be 66% duplication in there because I've just copied wholesale both my main storage and the results of previous attempts at organization in there, which includes a big pass with MusicBrainz Picard that only got half done, as well as the results of having pushed all my music to the Amazon cloud when they said it was going to be free, and then pulling it all back down when they changed their minds. It may go back up, but only after I've curated the hell out of it.
- Analysis
- Eliminate duplication
- Eliminate bad files
- Bring all files up to a minimum standard regarding tagging
- Move to some form of master storage
- Create a standard mechanism for preventing re-duplication
Well, the analysis step just finished and has produced a 5 MB JSON file with the salient details. I'll start working on identifying the files I can junk, and the files I need to curate.
Subscribe to:
Posts (Atom)